Python调用微信OCR,实现超高效实现批量提取图片
Python 2025-07-12
微信自带的OCR使用比较方便,且准确率较高,但是唯一不足的是需要手动截图之后再识别,无法批量操作,这里我们借助wechat-ocr这一开源工具,实现批量读取文件夹下的所有图片并提取文本的功能。下面介绍下操作步骤。
依赖环境
Windows系统,已安装最新版微信。
Python环境,推荐使用最新版本。
安装项目库
设置路径
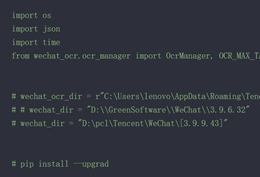
微信OCR程序路径:C:\Users\<你的用户名>\AppData\Roaming\Tencent\WeChat\XPlugin\Plugins\WeChatOCR\...
微信安装路径:例如 D:\GreenSoftware\WeChat\3.9.6.32
代码示例
依赖环境
Windows系统,已安装最新版微信。
Python环境,推荐使用最新版本。
安装项目库
pip install wechat-ocr
AI生成项目设置路径
微信OCR程序路径:C:\Users\<你的用户名>\AppData\Roaming\Tencent\WeChat\XPlugin\Plugins\WeChatOCR\...
微信安装路径:例如 D:\GreenSoftware\WeChat\3.9.6.32
代码示例
import os
import json
import time
from wechat_ocr.ocr_manager import OcrManager, OCR_MAX_TASK_ID
wechat_ocr_dir = "C:\\Users\\Administrator\\AppData\\Roaming\\Tencent\\WeChat\\XPlugin\\Plugins\\WeChatOCR\\7057\\extracted\\WeChatOCR.exe"
wechat_dir = "D:\\GreenSoftware\\WeChat\\3.9.6.32"
def ocr_result_callback(img_path:str, results:dict):
result_file = os.path.basename(img_path) + ".json"
print(f"识别成功,img_path: {img_path}, result_file: {result_file}")
with open(result_file, 'w', encoding='utf-8') as f:
f.write(json.dumps(results, ensure_ascii=False, indent=2))
def main():
ocr_manager = OcrManager(wechat_dir)
# 设置WeChatOcr目录
ocr_manager.SetExePath(wechat_ocr_dir)
# 设置微信所在路径
ocr_manager.SetUsrLibDir(wechat_dir)
# 设置ocr识别结果的回调函数
ocr_manager.SetOcrResultCallback(ocr_result_callback)
# 启动ocr服务
ocr_manager.StartWeChatOCR()
# 开始识别图片
ocr_manager.DoOCRTask(r"T:\Code\WeChat\OCR\Python\img\1.png")
ocr_manager.DoOCRTask(r"T:\Code\WeChat\OCR\Python\img\2.png")
ocr_manager.DoOCRTask(r"T:\Code\WeChat\OCR\Python\img\3.png")
time.sleep(1)
while ocr_manager.m_task_id.qsize() != OCR_MAX_TASK_ID:
pass
# 识别输出结果
ocr_manager.KillWeChatOCR()
if __name__ == "__main__":
main()
温馨提示:该项目仅供学习和个人使用,请勿将其用于任何商业用途。